直接映射缓存(Direct mapped cache)
直接映射缓存将ROM里地址按照一定的映射关系固定映射到1个cache line。如下图所示:

比如对于1个64KB的ROM,现在有1个512字节的cache,cache line的size为64byte,共8个cache line,物理地址将按以下结构进行拆分
| [15:9] | [8:6] | [5:0] |
| tag | cache line indxe | offset |
然后按照下面顺序进行数据操作
- 直接根据index判断当前对应的cache line。
- 将需要取数的地址tag同cache line的tag进行比较,判断数据是否命中。
- 如果没有命中,则刷新cache line的数据,否则直接返回数据。
直接映射的特点就是硬件结构简单,只需要根据地址即可快速判断出是否命中。但直接映射容易发生cache 颠簸(cache thrashing)的现象。
由于CPU程序的特定,大部分取值操作都发生在一段地址空间内,因此取值地址大概率会发生在同1cache line地址的映射区域内,对与上面的示例,当cpu在0x00fc和0x2fc之间反复取指令的时候,因为总是发生在cache line0,导致每次都没有命中,从而降低了cache效率。
全相联映射缓存(Full associative cache)
全相联映射情况下,每一个cache line都可以映射ROM内的任意一个块,示意图如下

比如对于同样1个64KB的ROM,现在有1个512字节的cache,cache line的size为64,共8个cache line,物理地址将按以下结构进行拆分
| [15:6] | [5:0] |
| tag | offset |
此时,tag的位宽将变为9bit。同样当CPU取数时,cache的操作如下:
- 将地址的tag同cache line存储的tag进行比对,遍历所有cache line的tag,判断是否命中。
- 如果没有命中,则更新某个cache line的内容,否则返回数据。
可以看出,全相联的情况下,灵活度很高,cache 利用率高,可以避免cache颠簸的发生,但同样存在以下缺点
需要存储的tag内容较多。当cache size较大时,会明显增大面积。
Cache控制器的复杂性增加,如果采用顺序查表的机制,查表延迟最多可达16个是时钟走起,采用并行查表,较多的比较器同样会增加面积以及恶化时序。因此适用于小缓存的cache。
组相联映射缓存(Set associative cache)
组相联通过多路直接映射的缓存同时工作来避免直接映射缓存带来的cache颠簸现象。示意图如下:
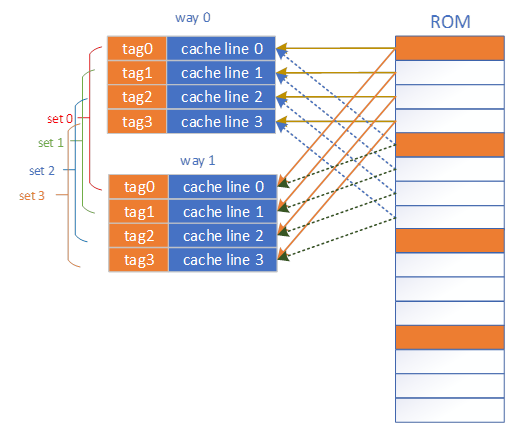
对比直接映射,cache分成两部分,分别为way0和way1,每个way采用直接映射,两个way相同index的cache line组成set。从set的角度看,它可以同时映射两个不同的块,从而避免了cache颠簸的现象。
同样对于1个64KB的ROM,现在有1个512字节的cache,cache line的size为64,共8个cache line,分成2个way,每个way4个cache line。物理地址将按以下结构进行拆分
| [15:8] | [7:6] | [5:0] |
| tag | set indxe | offset |
当CPU访问数据时,cache控制器然以下方式进行缓存判断:
- 直接根据set index索引到对应的set。
- 在set内根据tag进行遍历,判断set内是否有命中,如果命中则到对应的cache line内进行取数,否则更新某个cache line。
组相联在全相联和直接映射直接做了平衡,兼具两者的优点。